
Le noyau Linux ne cesse d’être utilisé dans des applications professionnelles diverses grâce à sa souplesse et ses performances. Un de ses points forts, c’est sa capacité à exploiter toute la mémoire mise à disposition pour accélérer les IO et l’accès aux fichiers lorsque les applications ne consomment pas tout. Voici ce qu’il faut savoir sur le buffer et le cache.
Voir l’utilisation mémoire
Aperçu par htop
Le programme htop est une amélioration de top , avec comme principal avantage une ergonomie améliorée et une meilleure lisibilité des ressources système. Sur le screenshot ci-dessous, on peut voire la charge processeur sur 24 cœurs, ainsi que l’utilisation mémoire (Mem) et de la partition d’échange (Swp).
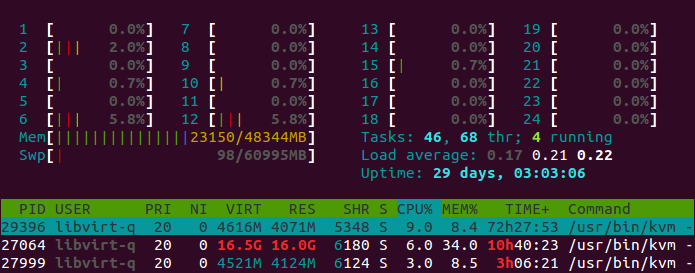
L’utilisation mémoire vue par htop
- En vert, nous avons la mémoire consommée par les processus lancés par le noyau et par les utilisateurs
- En bleu, nous avons les buffers IO
- En jaune, nous avons le cache de fichiers
La différence entre les buffers IO et le cache de fichiers n’est pas évidente à comprendre. Les buffers IO sont des fragments de données qui sont traitées par le noyau lors de l’utilisation de périphériques divers : disque dur, réseau, clé USB, lecteur cd-rom, etc. Le cache de fichiers consiste en des fichiers entiers qui sont souvent lus par le système, et que le noyau choisir de stocker en mémoire pour un accès plus rapide.
L’utilisation mémoire vue par free
La commande free permet d’afficher l’utilisation mémoire chiffrée. Voici la sortie qui correspond à la copie d’écran htop ci-dessus.
|
1 2 3 4 5 |
root@ordinateur:~# free -m total used free shared buffers cached Mem: 48344 47027 1316 0 197 23616 -/+ buffers/cache: 23213 25130 Swap: 60995 98 60897 |
On retrouve 23213 Mo utilisés par les applications (colonne used), 197 Mo utilisés par les buffers et 23616 Mo de cache de fichiers.
Agir sur la mise en cache des fichiers
Savoir si un fichier est en cache
Lors d’opérations répétitives, il est courant qu’une tâche prenne plus de temps lors de son premier lancement, que pour les lancements suivants. Cela peut être du à la mise en cache des fichiers qui est opérée par le noyau dans le but d’accélérer tout ce qui est possible.
Vient alors une question naturelle : est-ce que le fichier X ou Y est mis en cache, et dois-je attendre un gain de performances par sa mise en cache ?
Je ne connais pas d’outil par défaut GNU/Linux qui donne cette information, mais il existe le projet linux-ftools dont le code source est hébergé chez Google Code. Une fois compilé, ce projet fournit les exécutables linux-fincore , linux-fadvise et linux-fallocate .
Pour commencer, c’est avec linux-fincore que l’on peut savoir si un fichier a été mis en cache. Voici un exemple juste après la compilation de linux-ftools. On peut voir que les fichiers source ont bien été mis en cache pour accélérer cette compilation et la suivante, s’il devait y en avoir une (utilisez l’ascenseur horizontal pour voir les colonnes).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
root@ordinateur:/usr/local/src/linux-ftools/linux-ftools-2a7918d4b81b# ./linux-fincore --summarize --only-cached * filename size total_pages min_cached page cached_pages cached_size cached_perc -------- ---- ----------- --------------- ------------ ----------- ----------- aclocal.m4 34939 9 0 9 36864 100.00 Could not mmap file: autom4te.cache: No such device config.log 20929 6 0 6 24576 100.00 config.status 29894 8 0 8 32768 100.00 configure 171817 42 0 42 172032 100.00 configure.ac 864 1 0 1 4096 100.00 Could not mmap file: debian: No such device depcomp 17574 5 0 5 20480 100.00 INSTALL 9416 3 0 3 12288 100.00 install-sh 13184 4 0 4 16384 100.00 linux-fadvise 24378 6 0 6 24576 100.00 linux-fadvise.c 4875 2 0 2 8192 100.00 linux-fadvise.o 30808 8 0 8 32768 100.00 linux-fallocate 21462 6 0 6 24576 100.00 linux-fallocate.c 3252 1 0 1 4096 100.00 linux-fallocate.o 20992 6 0 6 24576 100.00 linux-fincore 44409 11 0 11 45056 100.00 linux-fincore.c 14967 4 0 4 16384 100.00 linux-fincore.o 79912 20 0 20 81920 100.00 linux-ftools.h 83 1 0 1 4096 100.00 Makefile 22577 6 0 6 24576 100.00 Makefile.am 209 1 0 1 4096 100.00 Makefile.in 21734 6 0 6 24576 100.00 missing 11135 3 0 3 12288 100.00 NEWS 65 1 0 1 4096 100.00 README 6001 2 0 2 8192 100.00 RELEASE 372 1 0 1 4096 100.00 showrlimit.c 1961 1 0 1 4096 100.00 waste_memory.c 699 1 0 1 4096 100.00 --- total cached size: 675840 |
Le programme linux-fadvise permet de donner des indications au noyau sur la manière dont tel ou tel fichier va être utilisé. Enfin, linux-fallocate semble être un clone de fallocate qui permet de créer un fichier avec une taille donnée, même volumineuse, en un rien de temps.
Influencer la mise en cache des fichiers
Pour configurer un serveur « aux petits oignons », on peut vite être tenté d’influencer le noyau pour forcer la mise en cache d’un fichier. Pour cela, le programme linux-fadvise permet de donner des « conseils » au noyaux pour retirer un fichier du cache ou peser pour sa mise en cache.
Encore plus brutal, le programme vmtouch permet de mettre un fichier en mémoire tout restant en tâche de fond pour veiller à ce que le fichier reste verrouillé en mémoire.
Lorsqu’il est lancé sans options, vmtouch ressemble fort à linux-fincore. Voici la sortie écran de chacun de ses programmes sur un exécutable fraîchement compilé, c’est justement l’exécutable « vmtouch ».
|
1 2 3 4 5 6 |
root@paul-ordinateur:/usr/local/src/vmtouch# linux-fincore ./vmtouch filename size total_pages min_cached page cached_pages cached_size cached_perc -------- ---- ----------- --------------- ------------ ----------- ----------- vmtouch 68822 17 0 17 69632 100.00 --- total cached size: 69632 |
|
1 2 3 4 5 |
root@ordinateur:/usr/local/src/vmtouch# vmtouch ./vmtouch Files: 1 Directories: 0 Resident Pages: 17/17 68K/68K 100% Elapsed: 0.000133 seconds |
On peux voir que 17 pages mémoires (68 Ko) sont consacrées à la mise en mémoire de cet exécutable.
Pour le faire tourner en tant que daemon qui verrouille un fichier en mémoire, voici la commande. Un possibilité tout à fait intéressante est de spécifier à vmtouch un répertoire complet.
|
1 2 3 |
root@ordinateur:/usr/local/src/vmtouch# vmtouch -dl ./vmtouch root@ordinateur:/usr/local/src/vmtouch# ps ax |grep vmtouch 27085 ? SLs 0:00 vmtouch -dl ./vmtouch |
Ces deux outils sont polyvalents, il permettent de mettre en mémoire n’importe quel fichier, quel que soit son type.
Vidage du cache de fichiers
Une petite commande concise comme on les aime pour vider le cache de fichiers. Après cela, plus de zone jaune dans l’occupation mémoire vue par htop.
|
1 |
root@ordinateur:~# echo 3 > /proc/sys/vm/drop_caches |
Cette commande n’aura pour effet que de dégrader les performances de lecture des fichiers qui étaient en cache. Cela sera utile notamment pour benchmarker des processus (comme une compilation) de manière répétable, sans que le cache ne vienne perturber les résultats.
Augmentation du cache de fichiers
Pour augmenter la proportion de cache des fichiers par rapport à l’utilisation mémoire par les processus, il suffit de s’abstenir de lancer des processus consommateurs. Dans htop cela se traduira par une barre jaune qui tend vers 100%. C’est une situation couramment rencontrée sur les serveurs de fichiers.
Il existe également un levier pour diminuer sa consommation mémoire en compressant les pages mémoire, voir mon article sur les optimisations mémoire sous Linux.
Les services d’accélération d’exécutables
Nous rentrons là dans une autre catégorie d’outils, les logiciels qui sont prévus pour mettre des fichiers binaires (ou des librairies partagées) en mémoire dans le but d’accélérer leur lancement. Bien entendu, linux-fadvise et vmtouch peuvent être utilisés dans ce sens mais il existe des outils moins minimalistes et plus adaptés à cette tâche.
memlockd
Le service memlockd a une action ciblée sur trois types de fichiers : les exécutables, leurs librairies linkées, et les fichiers de configuration. Le but est d’accélérer la réactivité de certaines applications.
Le fichier de configuration se situe dans /etc/memlockd.cfg et sa syntaxe est plutôt simple.
- Le préfixe + signifie : l’exécutable et ses librairies dynamiques.
- Le préfixe ? signifie : si ce fichier existe, et ne pas râler si ce n’est pas le cas.
- Le préfixe % signifie : inclure un fichier quelconque ou un répertoire complet (un seul niveau de récursion). Prévu à l’origine pour les fichiers de configuration.
|
1 2 3 4 5 6 7 |
+/bin/bash +/usr/sbin/sshd +/bin/busybox +/sbin/getty +/bin/login /etc/passwd /etc/shadow |
Selon son développeur, memlockd permettrait d’améliorer le comportement des machines aux attaques DDos en incluant les fichiers nécessaires au login en mémoire. Le fichier de configuration par défaut vise en effet à rendre le login plus réactif.
preload
Preload est un service qui se veut intelligent, il analyse le comportement de l’utilisateur pour comprendre tout seul les fichiers qui ont intérêt à être mis en mémoire. L’idée est bonne, essentiellement pour les postes de travail qui se verront optimisés en fonction de l’utilisation du moment.
ureadahead
Ce service est un peut particulier, ureadahead ne sert qu’à accélérer la phase de démarrage de l’ordinateur en mettant en mémoire les fichiers avant que la procédure de démarrage ne les demande. On appelle cela le « cache warmup », littéralement « préchauffage du cache ».
Cela est à différentier de readahead, qui est un paramètre que l’on retrouve sur les systèmes de fichiers, et qui permet de lire depuis le disque dur des portions du fichier en avance sur la zone requise à l’instant, afin d’améliorer les performances globales.
Conclusion
Tout cela est passionnant, mais s’il y a bien une chose que j’ai apprise à l’usage, c’est qu’il ne sert à rien de vouloir forcer le noyau à mettre des fichiers en cache. En effet, il est tellement bien conçu que la plupart du temps, les fichiers auxquels vous pensez sont déjà en mémoire, et le reste du temps c’est probablement vous qui avez tort de mettre tel ou tel fichier en cache.
Néanmoins, ce sont des éléments que tout administrateur système devrait connaître pour mieux comprendre et anticiper le comportement de l’OS, notamment lorsqu’on fait face à des écarts de performances entre deux exécutions d’une même action.
Maintenant que l’aspect du cache des fichiers est traité, du moins partiellement, que diriez-vous d’en savoir plus sur les optimisations mémoire sous Linux ?