
Le PCI Passthrough est une technique de virtualisation récente qui permet à un hyperviseur de connecter un périphérique PCI (ou PCIe) directement à un invité. Le périphérique est alors dédié avec un accès direct par l’invité. Voici les astuces de configuration à mettre en place pour faire fonctionner les cartes Nvidia les plus récentes avec une machine invité Windows virtualisée par KVM, testé ici avec une Inno3D Nvidia GTX 1050 et une EVGA Nvidia GTX 1060.
Sommaire
Introduction
Il faut savoir que Nvidia a délibérément rendu le PCI passthrough difficile avec les drivers Windows de ses cartes graphiques grand public. Il y a encore un an avec ESXi c’était encore chose impossible selon certaines sources. Selon Nvidia nous devrions acheter leur gamme pro Quadro pour effectuer cette opération. Même la licence d’utilisation de Nvidia interdit le déploiement cloud.
Bien qu’ils aient de moins bonnes performances énergétiques, il semblerait que les GPU AMD de la gamme RX soient moins bridés sur ce point.
La configuration décrite ci-dessous est réputée fonctionner à partir d’informations issues d’internet, et ce n’est pas toujours chose simple, mais il y a peut-être des étapes non-nécessaires. En effet, je me demande si certains paramètres ne sont pas justes utiles pour l’étape d’installation du driver Nvidia.
Pré-requis
La méthode ci-dessous a été réalisée avec l’hyperviseur KVM sur une plateforme matérielle récente (processeur Xeon E5 v3) et une distribution Linux à jour (Debian 9) avec un noyau supérieur à 4.1 (ici 4.9). La carte graphique retenue est une Inno3D 1-slot Nvidia GTX 1050 mais n’importe quelle carte graphique grand public récente (compatible UEFI) devrait convenir.
Un autre ordinateur moins récent a été configuré avec succès sur ancienne architecture CPU Bulldozer, un AMD FX-8350 socket AM3+ avec une EVGA GTX 1060, toujours sous Debian 9.
L’essentiel semble être de disposer d’un processeur et carte mère compatible IOMMU (extensions Intel VT-d ou AMD-Vi).
Il faudrait idéalement s’assurer que la carte graphique est capable de rebooter sans extinction de la machine hôte. Certaines cartes AMD n’en sont pas capables.
Configuration de l’hyperviseur
Les modules noyau
Pour commencer il faut s’assurer que l’hyperviseur KVM active bien ses extensions Intel Vt-d ou équivalent AMD-Vi qui équivalent pour le BIOS et pour Linux à IOMMU. Si une option du BIOS est nommée ainsi, il faut l’activer.
Ensuite on ajoute l’option de noyau intel_iommu=on ou amd_iommu=on sur la ligne GRUB_CMDLINE_LINUX_DEFAULT de /etc/defaults/grub . Un update-grub2 est requis ensuite.
Après un reboot on pourra voir passer une référence à « IOMMU » ou à « DMAR » dans dmesg mais ce n’est pas toujours le cas. La présence des fichiers suivants semble indiquer que IOMMU est activé dans le noyau.
|
1 2 3 4 5 6 |
root@serveur:/# ls /sys/class/iommu/*/ /sys/class/iommu/dmar0/: devices intel-iommu power subsystem uevent /sys/class/iommu/dmar1/: devices intel-iommu power subsystem uevent |
Le script suivant trouvé sur le wiki Arch permet de montrer les groupes d’isolation IOMMU. Il faut que le périphérique en passthrough soit isolé. Si ce n’est pas le cas on peut utiliser ACS mais je n’en parlerai pas ici.
|
1 2 3 4 5 6 7 |
#!/bin/bash shopt -s nullglob for d in /sys/kernel/iommu_groups/*/devices/*; do n=${d#*/iommu_groups/*}; n=${n%%/*} printf 'IOMMU Group %s ' "$n" lspci -nns "${d##*/}" done; |
On rajoute également les fichiers suivants afin d’obliger le chargement de modules avec le noyau.
|
1 2 |
root@serveur:/# cat /etc/modprobe.d/vfio.conf options vfio-pci ids=10de:1c81,10de:0fb9 disable_vga=1 |
On reconnait 10de:1c81 et 10de:0fb9 qui sont les adresses matérielles associées au GPU et visibles entre crochets par un lspci -nn . Si vous voyez sur internet des références à pci-stub, sachez que c’est une méthode plus ancienne et que désormais vfio-pci est recommandé.
|
1 2 |
root@serveur:/# cat /etc/modprobe.d/kvm.conf options kvm ignore_msrs=1 |
De plus, j’ajoute les modules vfio, vfio_iommu_type1 et vfio_pci dans /etc/initramfs-tools/modules afin de les forcer au démarrage du noyau.
Après un update-initramfs -u puis reboot les modules suivants sont chargés.
|
1 2 3 4 5 6 |
root@serveur:~# lsmod |grep vfio vfio_pci 45056 0 irqbypass 16384 2 kvm,vfio_pci vfio_virqfd 16384 1 vfio_pci vfio_iommu_type1 20480 0 vfio 28672 2 vfio_iommu_type1,vfio_pci |
Le script suivant trouvé sur Reddit permet d’afficher les modules noyau avec leurs paramètres (ici kvm avec ignore_msrs et vfio-pcu avec ids et disable_vga).
|
1 2 3 4 5 6 7 8 9 10 11 |
#!/bin/bash cat /proc/modules | cut -f 1 -d " " | while read module; do \ echo "Module: $module"; \ if [ -d "/sys/module/$module/parameters" ]; then \ ls /sys/module/$module/parameters/ | while read parameter; do \ echo -n "Parameter: $parameter --> "; \ cat /sys/module/$module/parameters/$parameter; \ done; \ fi; \ echo; \ done |
Libvirt avec OVMF
Les cartes Nvidia les plus récentes nécessiteront un BIOS virtualisé UEFI (nommé ovmf), et pas le SeaBIOS par défaut. En tout cas je n’ai jamais réussi à faire fonctionner le passthrough Nvidia avec SeaBIOS malgré de multiples tentatives.
|
1 |
root@serveur:~# apt-get install ovmf |
On dé commente les lignes suivantes dans /etc/libvirt/qemu.conf .
|
1 2 3 4 5 |
nvram = [ "/usr/share/OVMF/OVMF_CODE.fd:/usr/share/OVMF/OVMF_VARS.fd", "/usr/share/OVMF/OVMF_CODE.secboot.fd:/usr/share/OVMF/OVMF_VARS.fd", "/usr/share/AAVMF/AAVMF_CODE.fd:/usr/share/AAVMF/AAVMF_VARS.fd" ] |
Dump de la ROM de la carte graphique
On peut trouver sur internet la manipulation permettant de copier le micrologiciel en ROM de la carte graphique dans un fichier qui sera présenté par l’hyperviseur à la machine invité. La commande suivante permet de faire cette opération uniquement si le GPU n’est pas le GPU principal de l’hyperviseur ni utilisé par elle.
|
1 2 3 |
root@serveur:/# echo 1 > /sys/bus/pci/devices/0000\:08\:00.0/rom root@serveur:/# cat /sys/bus/pci/devices/0000\:08\:00.0/rom >image.rom root@serveur:/# echo 0 > /sys/bus/pci/devices/0000\:08\:00.0/rom |
Ensuite on peut vérifier que la ROM est correcte avec l’utilitaire rom-parser à compiler depuis les sources github.
|
1 2 3 4 5 6 7 8 9 |
root@serveur:/# /usr/local/bin/rom-parser image.rom Valid ROM signature found @0h, PCIR offset 1a0h PCIR: type 0 (x86 PC-AT), vendor: 10de, device: 1c81, class: 030000 PCIR: revision 0, vendor revision: 1 Valid ROM signature found @f000h, PCIR offset 1ch PCIR: type 3 (EFI), vendor: 10de, device: 1c81, class: 030000 PCIR: revision 3, vendor revision: 0 EFI: Signature Valid, Subsystem: Boot, Machine: X64 Last image |
On voir ici « type 3 (EFI) » ce qui signifie que la carte est compatible UEFI. Si elle ne l’était pas il faudrait que je mette à jour la ROM de la carte graphique dans l’espoir qu’elle le devienne. Normalement les cartes après 2014 ne devraient pas poser de problème.
|
1 2 |
root@serveur:/# ls -l image.rom -rw-r--r-- 1 libvirt-qemu libvirt-qemu 129024 avril 16 15:53 image.rom |
Sa taille est d’approximativement 128 Ko. Les ROM que l’on trouve sur internet font parfois 256 Ko et pour les utiliser on pourrait utiliser sans garantie l’utilitaire NVIDIA-vBIOS-VFIO-Patcher pour les convertir au format 128 Ko.
Après quelques tests, je pense que cette manipulation de dump ROM n’est pas nécessaire pour ma GTX 1050, et cela a été confirmé aussi avec une GTX 1060.
Création de la machine virtuelle Windows
Dans l’idée on va utiliser plusieurs astuces pour faire croire à la machine virtuelle qu’elle n’est pas virtualisée, et éviter ainsi que le driver Nvidia sous Windows bloque le GPU.
Pour ce faire j’utilise virt-manager pour créer une machine virtuelle minimale. Demander à modifier les réglages avant de démarrer la VM afin d’être en mesure de choisir le BIOS adéquat. Je choisis les options suivantes :
- Microprogramme (BIOS) : UEFI x86_64: /usr/share/OVMF/OVMF_CODE.fd
- Chipset i440FX (Q35 non testé ici)
- Processeur modèle : host-passthrough (facultatif)
- Processeur topologie manuelle : 1 socket, 4 cœurs, 2 fils/threads (facultatif)
- Les 2 périphériques PCI correspondants à la carte graphique sont ajoutés (GPU et sortie audio numérique HDMI).
- Affichage VNC (pas spice).
- Video VGA (pas QXL).
Ensuite en éditant la configuration XML on peut vérifier les réglages définis par virt-manager, puis en ajouter de nouveaux comme : « hyperv vendor_id », « kvm hidden », et « hostdev rom[« file »] ».
De mon coté c’est ici que je définis un disque avec un zvol ZFS mais c’est hors-sujet.
|
1 2 3 4 5 |
<os> <type arch='x86_64' machine='pc-i440fx-2.8'>hvm</type> <loader readonly='yes' type='pflash'>/usr/share/OVMF/OVMF_CODE.fd</loader> <nvram>/var/lib/libvirt/qemu/nvram/gpu2_VARS.fd</nvram> </os> |
|
1 2 3 4 5 6 7 8 9 10 11 |
<features> <acpi/> <apic/> <hyperv> <vendor_id state='on' value='1234567890ab'/> </hyperv> <kvm> <hidden state='on'/> </kvm> <vmport state='off'/> </features> |
|
1 2 3 |
<cpu mode='host-passthrough'> <topology sockets='1' cores='4' threads='2'/> </cpu> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<hostdev mode='subsystem' type='pci' managed='yes'> <source> <address domain='0x0000' bus='0x08' slot='0x00' function='0x0'/> </source> <rom bar='on' file='/image.rom'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <source> <address domain='0x0000' bus='0x08' slot='0x00' function='0x1'/> </source> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0'/> </hostdev> |
Pour information, j’ai testé de retirer les éléments de configuration suivants après installation des drivers Nvidia, sans soucis : rom[bar=’on’] ; rom[file=’/image.rom’] ; vmport. Idem pour cpu[mode=’host-passthrough’] qui n’est pas indispensable.
Pour faire court le BIOS OVMF, le paramètre kvm[hidden state=’on’], et vendor_id me semblent indispensables.
Voici ci-dessous le fichier xml entier qui fonctionne sur mon matériel. Certaines valeurs sont cachées comme les uuid et MAC réseau.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 |
<domain type='kvm'> <name>gpu</name> <uuid>43b[...]</uuid> <title>gpu</title> <memory unit='KiB'>16777216</memory> <currentMemory unit='KiB'>16777216</currentMemory> <vcpu placement='static'>8</vcpu> <os> <type arch='x86_64' machine='pc-i440fx-2.8'>hvm</type> <loader readonly='yes' type='pflash'>/usr/share/OVMF/OVMF_CODE.fd</loader> <nvram>/var/lib/libvirt/qemu/nvram/gpu_VARS.fd</nvram> </os> <features> <acpi/> <apic/> <kvm> <hidden state='on'/> </kvm> </features> <cpu mode='custom' match='exact'> <model fallback='allow'>Haswell-noTSX</model> </cpu> <clock offset='localtime'> <timer name='rtc' tickpolicy='catchup'/> <timer name='pit' tickpolicy='delay'/> <timer name='hpet' present='no'/> </clock> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <pm> <suspend-to-mem enabled='no'/> <suspend-to-disk enabled='no'/> </pm> <devices> <emulator>/usr/bin/kvm</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw'/> <source file='/dev/zvol/data/gpu2'/> <target dev='vda' bus='virtio'/> <boot order='1'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x08' function='0x0'/> </disk> <disk type='file' device='cdrom'> <driver name='qemu' type='raw'/> <source file='/var/lib/libvirt/images/iso/virtio-win-0.1.141-1.iso'/> <target dev='hdb' bus='ide'/> <readonly/> <address type='drive' controller='0' bus='0' target='0' unit='1'/> </disk> <controller type='usb' index='0' model='ich9-ehci1'> <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x7'/> </controller> <controller type='usb' index='0' model='ich9-uhci1'> <master startport='0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0' multifunction='on'/> </controller> <controller type='usb' index='0' model='ich9-uhci2'> <master startport='2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x1'/> </controller> <controller type='usb' index='0' model='ich9-uhci3'> <master startport='4'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x2'/> </controller> <controller type='pci' index='0' model='pci-root'/> <controller type='ide' index='0'> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x1'/> </controller> <controller type='virtio-serial' index='0'> <address type='pci' domain='0x0000' bus='0x00' slot='0x0a' function='0x0'/> </controller> <interface type='network'> <mac address='00:00:00:00:00:00'/> <source network='default'/> <model type='virtio'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/> </interface> <serial type='pty'> <target port='0'/> </serial> <console type='pty'> <target type='serial' port='0'/> </console> <channel type='unix'> <target type='virtio' name='org.qemu.guest_agent.0'/> <address type='virtio-serial' controller='0' bus='0' port='1'/> </channel> <input type='tablet' bus='usb'> <address type='usb' bus='0' port='1'/> </input> <input type='mouse' bus='ps2'/> <input type='keyboard' bus='ps2'/> <graphics type='vnc' port='-1' autoport='yes'> <listen type='address'/> </graphics> <video> <model type='vga' vram='16384' heads='1' primary='yes'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/> </video> <hostdev mode='subsystem' type='pci' managed='yes'> <source> <address domain='0x0000' bus='0x08' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <source> <address domain='0x0000' bus='0x08' slot='0x00' function='0x1'/> </source> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0'/> </hostdev> <memballoon model='virtio'> <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/> </memballoon> <rng model='virtio'> <backend model='random'>/dev/urandom</backend> <address type='pci' domain='0x0000' bus='0x00' slot='0x09' function='0x0'/> </rng> </devices> </domain> |
Installation de la machine virtuelle Windows
Une machine virtuelle Windows installée avec un SeaBIOS aura bien du mal à booter en OVMF. A cause de cela une conversion P2V est difficile. Le mieux est d’installer la VM avec le BIOS OVMF d’origine.
Les pilotes matériels virtio peuvent être ajoutés lors de l’installation avec l’image ISO citée dans cet article sur les pilotes.
Après installation du driver Nvidia sous Windows, l’affichage VNC avec carte VGA ne fonctionnera plus car le GPU sera privilégié. En connexion HDMI ou RDP à distance, le Gestionnaire de périphériques devrait afficher le GPU correctement sans erreur 43.

La VM Windows a planté là ? Non son affichage VNC n’est plus utilisable au profit du GPU matériel.
Le programme GPU-Z devrait afficher toutes les fréquences normalement ainsi que toutes les sondes (et pas seulement 2 à 0 MHz).
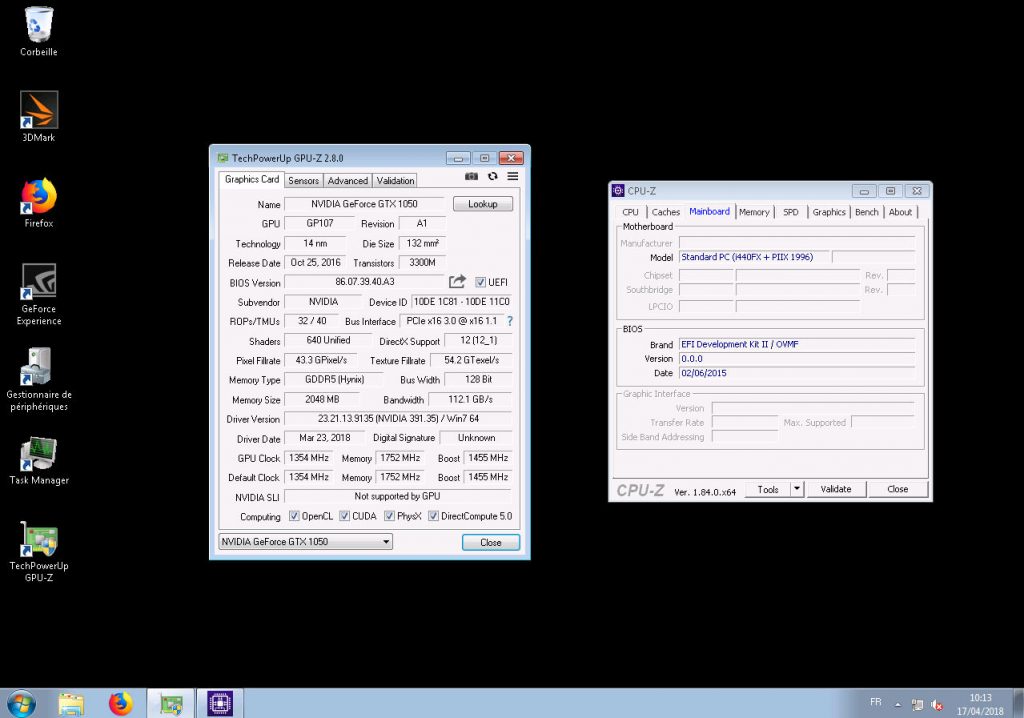
GPU-Z qui affiche les bonne valeurs et CPU-Z qui indique le BIOS OVMF
De nombreuses possibilités offertes
Avec une machine virtuelle qui dispose d’un GPU en PCI passthrough, plein de possibilités s’offrent à vous : configuration bureau dualhead, calculs CUDA, minage cryptomonnaies, exploitation de l’encodage H264 Nvenc, j’en passe et des meilleures.

Avec ça on peut en mettre des GPU 1-slot (carte-mère Supermicro X8DTH-iF)
Un GPU matériel ne peut être affecté qu’à une seule VM en même temps. Libvirt vous autorisera tout de même l’affectation du même GPU à plusieurs VM à condition qu’elles ne tournent pas en même temps. Cela offre la possibilité d’affecter un GPU à une VM en temps voulu, un principe qui doit probablement être mis en place par des services de cloud gaming.
Lorsqu’il n’est pas utilisé par une machine virtuelle, on peut se servir du GPU sur l’hyperviseur à condition de charger-décharger vfio à la demande. Le projet bumblebee (implémentation libre de Nvidia Optimus) permet de bénéficier des performances du GPU sans qu’aucun écran ne soit connecté dessus.
En général, le gpu passthrough implique d’utiliser le GPU avec ses ports externes mais une option se présente pour afficher l’image générée par le GPU de la VM en mode fenêtré sur l’hyperviseur : looking glass.
Alternative plus simple
Le présent article présente la configuration complète pour KVM sur Debian 9 mais il existe des distributions clé-en-mains qui permettent de faire l’équivalent avec moins de configuration : il s’agit de Proxmox, orientée virtualisation, et de UnRAID, orientée stockage et également virtualisation.
J’ai notamment déjà lu un article dans Hardware Mag et vu une vidéo de Linus Tech Tips qui présente la méthode avec UnRAID.
Sources
- PCI passthrough via OVMF, wiki.archlinux.org
- Pci passthrough, pve.proxmox.com
Bonjour, j’essaie de suivre votre tutoriel et je suis bloqué à l’étape suivante :
Après un update-initramfs -f puis reboot les modules suivants sont chargés.
root@serveur:~# lsmod |grep vfio
vfio_pci 45056 0
irqbypass 16384 2 kvm,vfio_pci
vfio_virqfd 16384 1 vfio_pci
vfio_iommu_type1 20480 0
vfio 28672 2 vfio_iommu_type1,vfio_pci
la commande update-initramfs -f ne semble pas valide ? j’ai donc tenté -u à la place de -f mais après reboot « lsmod |grep vfio » ne retourne rien
merci pour votre aide
resolved by adding
vfio
vfio_iommu_type1
vfio_pci
vfio_virqfd
to /etc/modules-load.d/modules.conf and reboot
Bonjour, c’était bien update-initramfs -u et j’ai corrigé la coquille.
J’ai précisé les modules chargés sur ma distribution afin de les forcer si besoin, comme vous l’avez fait.
Bonjour, vraiment super tutoriel !
J’aimerais faire passer ma GTX 1050 à travers virt-manager sur un Win10… mais ça bloque un peu ^^
Alors déjà voici les différents retours de commande : grub, lspci….
Donc pour le dump de la rom ça bloque (voir Pastebin), également lorsque j’ajoute le 0000:00:01:00 lors de l’installation qui est dans le même groupe que ma carte graphique Qemu me dit :
« Impossible de terminer l’installation : « Failed to bind PCI device ‘0000:00:01.0’ to vfio-pci: No such device » »
Et ça ne veut donc pas aller plus loin…
Si vous pouviez m’apporter de l’aide, un grand merci, car j’en ai marre de faire 300 tutos différents pour tenter de passthrough ma cg ! 😀
Voici mon Pastebin : https://pastebin.com/WY717d35
Bonjour, vous devez mettre en passthrough votre carte Nvidia qui n’est pas ‘0000:00:01.0’ (bus PCI) mais ‘0000:01:00.0’.
Son adresse est bien 10de:1c8d et je pense que 8086:1901 n’a rien à faire dans vfio-pci. Par contre vous pouvez ajouter l’adresse de la partie son de la carte que je ne vois pas.
Ne tentez pas de dump ROM avant d’avoir une VM qui tourne. Le dump ROM, c’est si jamais GPU-Z vous affiche les sensors à zéro avec erreur driver 43. De toutes manières on ne peut pratiquer un dump que si le GPU est le second de la carte mère et non-utilisé par le noyau (relisez le paragraphe correspondant). lcpci -vv pour s’en assurer (chercher « driver in use »).
Effectivement moi non plus je n’ai pas trouvé la partie son, on fera sans :p
Mmm, j’ai mis 8086:1901 en plus car il est dans le même groupe IOMMU (1) que le 10de:1c8d…
Du coup il n’y a que la CG en 0000:01:00.0, j’ai un stockage de 45Go en VirtIO, une entrée CD/DVD avec l’ISO de windows en SATA, et une autre entrée CD/DVD avec l’iso des drivers. L’iso de Windows est sensée booter un 1er mais je reste bloqué dans l’UEFI Shell… impossible de booter, je n’ai que des BLK sur ma mapping table.
Pourriez-vous m’indiquer comment booter sur l’iso de win à partir de l’uefi shell ?
Merci !
Cela peut aider de configurer l’ordre du périphérique de boot avec virt-manager. Ensuite je ne me souviens plus s’il suffit d’attendre que l’UEFI passe la main au CD, ou s’il faut appuyer sur une touche. Normalement cet UEFI ne devrait pas être différent des ordinateurs physiques. En cas de problème avec VirtIO en C: à l’install, j’utilise un disque IDE, puis installe les drivers VirtIO sur un second disque D:, avant de basculer le C: de IDE à VirtIO.
Bonjour ! (de retour de vacances)
J’ai tout essayé, ce que tu as dis et dans tous les sens, rien n’y va je fini toujours par rester bloqué dans cet UEFI Interactive Shell !!!!
Est-il possible que tu me donnes ton fichier XML, voir ce que ça donne si je le met sur mon pc stp ?
J’avance vers une possible sortie de l’UEFI Shell.
J’ai créé une clé USB bootable de l’ISO. Et je fais passer la clé USB pour un disque dans virt-manager : maintenant le Shell voit ma clé usb, peut y naviguer et je vois le bootx64.efi (qui est censé permettre de booter) !
Problème : en lançant bootx64.efi, rien ne se passe :'(
Il faut configurer l’ordre de boot dans virt-manager et ne permettre de démarrer que sur le CD. Après le premier reboot de l’installateur on modifiera pour le disque dur.
J’ai ajouté ma config XML complète mais je crains que cela ne t’avance pas plus. As-tu bien installé et configuré ovmf sur l’hyperviseur ?
Et avec une autre version de Windows ou Debian, cela donne quoi ?
Attention à ce bug (voir ici aussi) que je n’ai pas personnellement rencontré. Chercher « Windows 10 ovmf » pour plus de ressources.
Hello , I have same motherboard x8dth-if .
but i need to pass acpi=off in grub to boot debian 9 . so iommu will not work !
can you share your bios configuration ?
Hello, I do not know if ACPI is needed in order to use IOMMU groups. I do not use this motherboard anymore, but I used a newer one from Supermicro with success. BIOS configuration is standard, with everything activated or set on « auto ».
Thanks for your reply , bad luck ! i have headache with board for 2 weeks until now . I can’t figure out how to solve this 🙁
Hi Akaber,
I haven’t the same MB that you. But, If you have in your bios the choice on where graphically boot configuration is possible, force the use of your dedicated linux GC for booting. For me, that solved my problem. In my cas, i boot only on the CPU integrated chipset, and no more problem with ACPI
Perso j’étais bloqué sur la partie installation du driver NVIDIA, le souci était que dans les Hardware Ids j’avais un SUBSYSTEM à 00000000. Etant en dual boot j’ai pris la valeur de ce champs dans windows, l’ai convertie en décimal et ajouté dans ma conf avec VIRSH les commandes qemu ci dessous entre et :
ne pas oublier de mettre dans l’entete
des jours et des jours de galère pour trouver cette manip ! voilà pour ma part, après à voir si le reste fonctionne
Je n’ai pas pour habitude de commenter les articles, mais là je me devais de le faire…
Un grand merci, vous m’avez évité de devenir fou. J’ai acheté une petite carte graphique, une GT 1030 pour faire du passthrough sur ma fedora 35, et malgré tous les tutos et guides, ça ne fonctionnait pas, j’avais une erreur 12 sur la carte graphique sous windows (problème de ressources disponibles).
Grâce à vos explications, notamment pour le bios UEFI auquel je n’avais pas pensé, le fait de cacher la virtualisation, l’ovmf etc.., j’ai réussi enfin .
Encore merci à vous, et bonne continuation.
P.S. : Je n’ai pas utilisé de dump du bios de ma carte (gt 1030) et ça a fonctionné parfaitement. Comme la commande pour le dumper sous linux me renvoyait une erreur d’entrée sortie, je l’ai dumpé sous windows avec un programme gratuit, gpu-z, si cela peut aider des personnes qui en auraient besoin. A noter que mon bios faisait 256ko.
Bonsoir,
J’ai rencontré un petit soucis en utilisant un switch hdmi sur un de mes écrans.
En effet, lors du retour à l’hdmi du kvm sous windows, si la barre des taches, le menu et les icônes étaient présentes, les fenêtres n’apparaissaient plus (la miniature aero pourtant oui). C’est comme si les fenêtres avaient été envoyées autre part et impossible d’y accéder.
Donc je poste le workaround, si cela arrivait à d’autres ayant suivi ce super tutoriel, si cela peut aider. En fait en regardant le gestionnaire de périphériques, je me suis rendu donc qu’en plus de la geforce, windows possédait une carte graphique (avec un nom du genre carte graphique de base windows, vnc?), et un deuxième moniteur.
Les désactiver a résolu le problème pour moi. Par contre, je ne sais pas si cela a un impact quelconque.
Bonne soirée et encore merci.
En effet pour ma part quand tout fonctionne, je désactive la carte graphique virtuelle dans KVM (qxl pour Spice, ou autre) pour que Windows ne voit plus que la carte physique en pass-through. Et j’active un lien série qui est correctement reconnu par Windows et qui affiche des informations sur la phase de boot. Bonne continuation !